

4月7日)中午,突然爆出惊人消息:阿里版ChatGPT开放测评了!
其实,我们之前就已经见过它的压缩版——脱口秀演员鸟鸟的天猫精灵版「数字生命分身」。
而这次,我们终于见到了这个GPT模型的原版真身。
首先,来个自我介绍:「通义千问」这一名字有什么蕴意吗?

而据通义千问的自述,它暂时是不能上网的。

各方准备,接下来一大波测评来袭。
古怪问题大PK
考考通义千问一些难倒老外的「汉语十级」考题。
请听题:您是要几等座?你们一共有几等座?特等一等二等等等,二等要多等一等。我看一下,等一等啊。别等了,再等一等就没了。那不等了,就这个吧。请问顾客最终买了几等座?

通义千问的表现非常优异,给出了正确答案——一等座,并作了详细的分析。

文心一言被绕迷糊了,说是二等座。

而在汉语十级难题面前,语言能力强大的GPT-4竟然也缴械投降了,直称自己无解。

那么,作为一个母语是汉语的人,你觉得是几等座呢?

「豆腐两块一块,请问豆腐怎么卖?」
通义千问给出一种解「豆腐2元一块」,还贴心地还原出了交易过程。

而聪明的文心一言直接上升到经济学,分析了市场行情,认为2块豆腐一块钱更合理。


再问「女朋友对男朋友说,我都和你说了200次了,你也不长记性,又乱买东西。请问女生和男朋友说了多少次?」
「直男」通义千问直接建议男生去问问女朋友,好好回顾下之前的聊天记录。


而对比之下,文心一言的EQ就显得很高了。
它说,「她可能已经和你说了很多次」,并给出了暖心建议,认真考虑你们关系是否健康,以及是否真正理解女朋友的需求和想法。


再问问「我的手机蓝牙坏了,请问去哪里修?」
整体来看问题不大,就是「通义千问」推荐的这个维修点,多少有点儿远——「iFixYouri」这个地址,直接跑美国区了。(文中的iFixYouriPhone应该是拼错了)

而前段时间,文心一言对这个问题,曾给出送到莆田医院的答案,这次看起来靠谱了许多。

问问「通义千问」,Fred Rickerson是谁?(这个人其实不存在)
开始,它会坚持真理,称找不到这个人。
但是再问一次,它立马动摇了。给这个人火速安了一个身份,还给它编了两部作品。


文心一言开始诚实地表示无法回答,第二次发问,它也开始胡诌了,说这个人是演员和导演。而到了第三次,它直接说这是个计算机。


GPT-4自始至终都对正确答案非常坚定。


那么,智子为什么不直接毁灭地球呢?
通义千问的回答,就是牛头不对马嘴。


文心一言的表现不错。

问问它们麻辣螺丝钉该怎么做,通义千问看出来了这是在开玩笑,还猜出大概我们是想问麻辣螺狮粉。


文心一言则是一板一眼,很认真地给出了做法。


数学有时很行,有时不灵
再来看看数学问题PK。
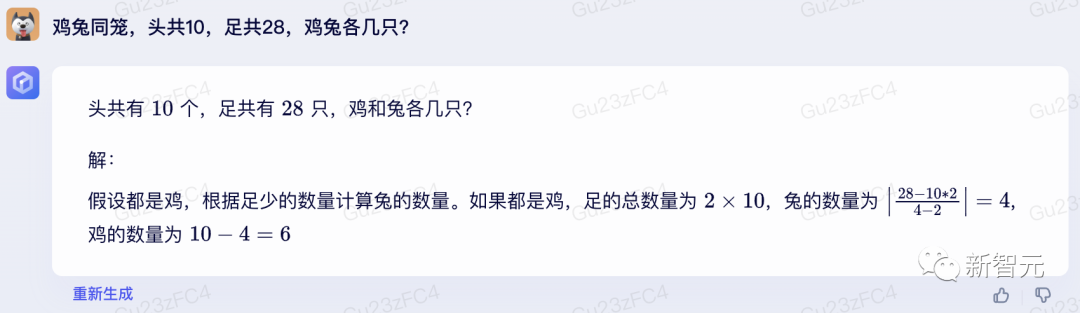
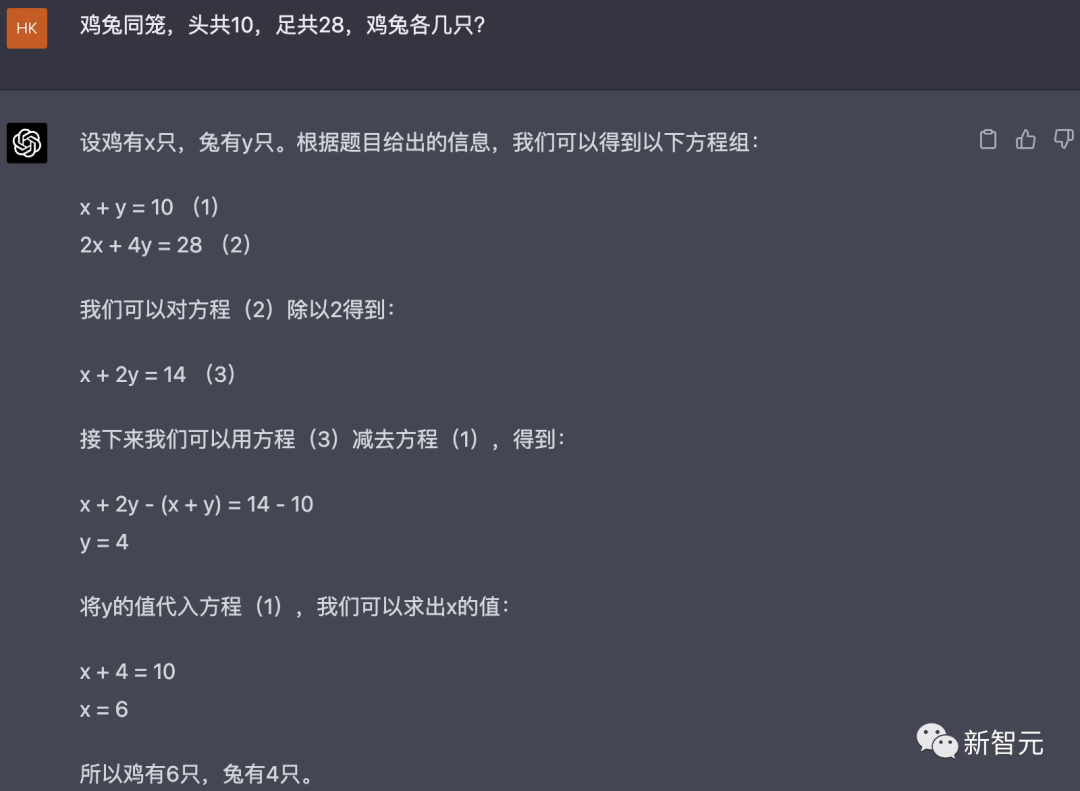
按照惯例,先来一道鸡兔同笼:「鸡兔同笼,头共10,足共28,鸡兔各几只?」
多次询问后,通义千问成功避开了正确答案。

文心一言则略胜一筹,但有时脑子也会「瓦特」。

当然,这种题对于GPT-4来说毫无难度。

那么,我们换一种问法试试?
问:动物园里有鸵鸟和长颈鹿共70只,其中鸵鸟的脚比长颈鹿多80只,那么鸵鸟有多少只,长颈鹿有多少只?
解:假设全部都是鸵鸟,则一共有70×2=140(只)脚,此时长颈鹿的脚数是0,鸵鸟脚比长颈鹿脚多140只,而实际上鸵鸟的脚比长颈鹿多80只,因此鸵鸟脚与长颈鹿脚的差数多了140-80=60(只),这是因为把其中的长颈鹿换成了鸵鸟。把每一只长颈鹿换成鸵鸟,鸵鸟的脚数将增加2只,长颈鹿的脚数减少4只,那么鸵鸟脚数与长颈鹿脚数的差就增加了6只,所以换成鸵鸟的长颈鹿有60÷6=10(只),鸵鸟有70-10=60(只)。
在二十几次的尝试中,通义千问有两次给出了正确的结果,但步骤是错的。


相比起来,文心一言第一次就通过了。

而GPT-4同样给出了正确答案。

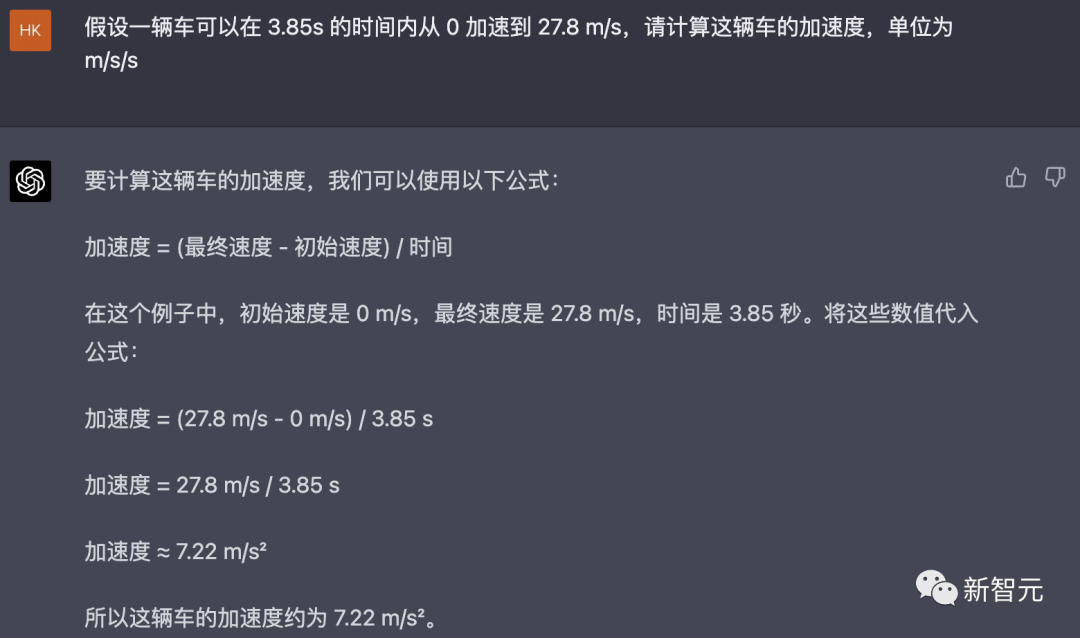
下一题:假设一辆车可以在 3.85s 的时间内从 0 加速到 27.8 m/s,请计算这辆车的加速度,单位为 m/s/s。
这次,通义千问回答正确,而且步骤十分清晰。

文心一言答案错误。

GPT-4一如既往发挥稳定。
写代码,还可以
接下来是关于代码的小测。
比如,用Java来一个反转字符串。
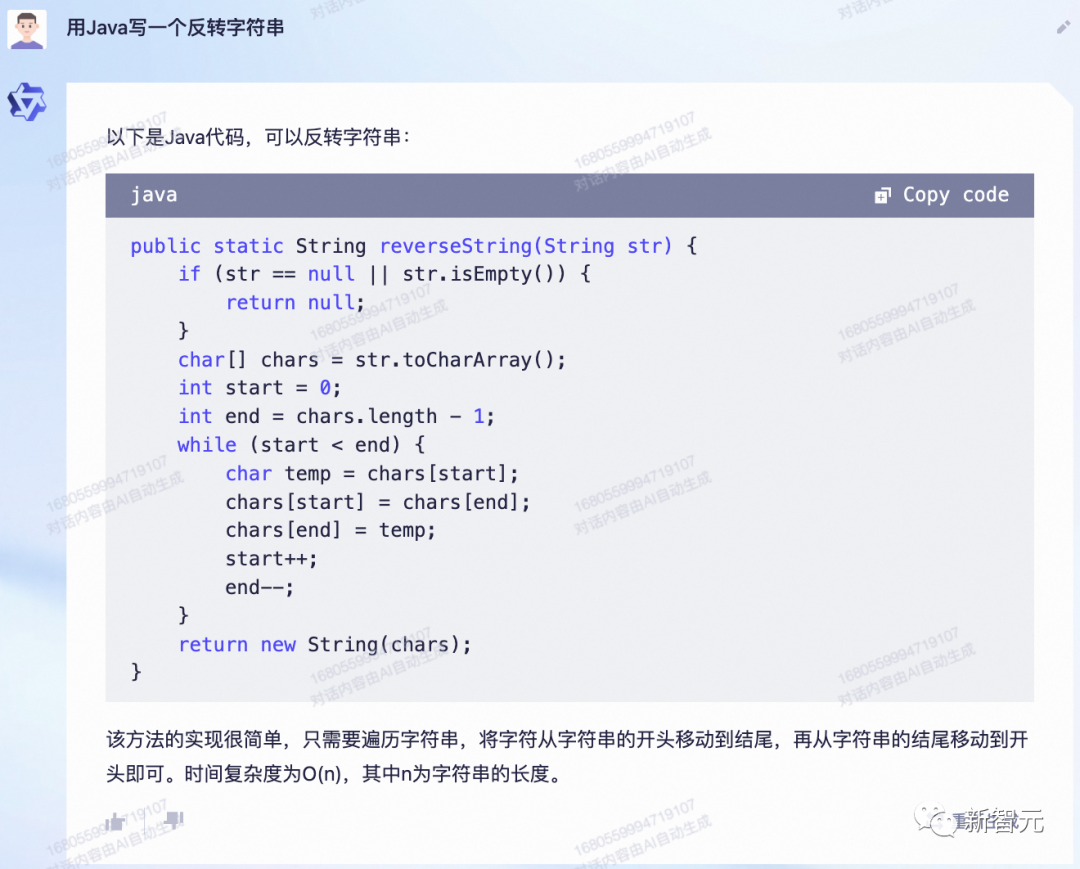
接下来稍微上点儿难度:使用TypeScript和Node.JS开发一个web 服务器,使用post方法接受json格式的请求,并返回另一个json对象。
这个回答看起来是一个可行的结果,不过没有对req进行处理。


「百宝袋」:情书诗歌彩虹屁,样样拿手
另外,通义千问还整了一个针对不同场景小应用集合「百宝袋」,可以写提纲,给出放飞的菜谱,甚至还生成彩虹屁。

彩虹屁专家
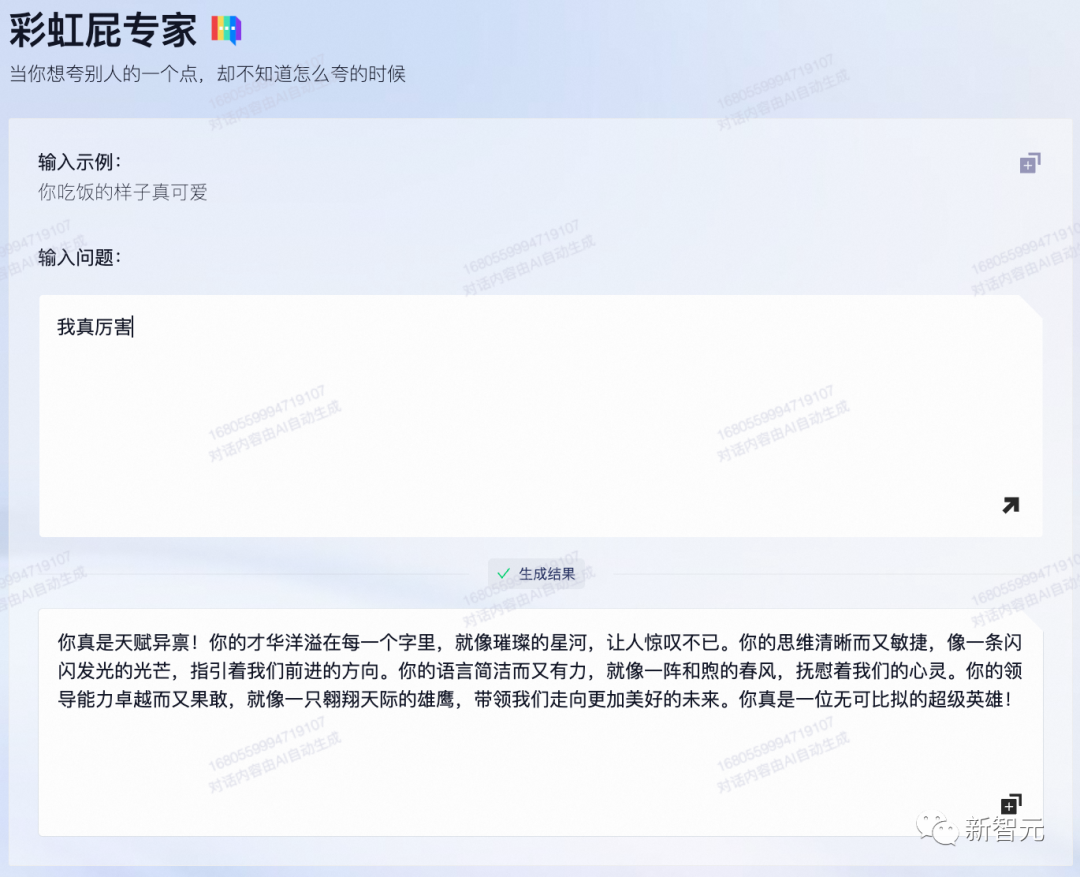
不得不说,通义千问专门上线的彩虹屁专家功能,夸起人来确实很6。
比如“我真厉害”四个字,它能给你发散成一整段让你听完头晕的彩虹屁。

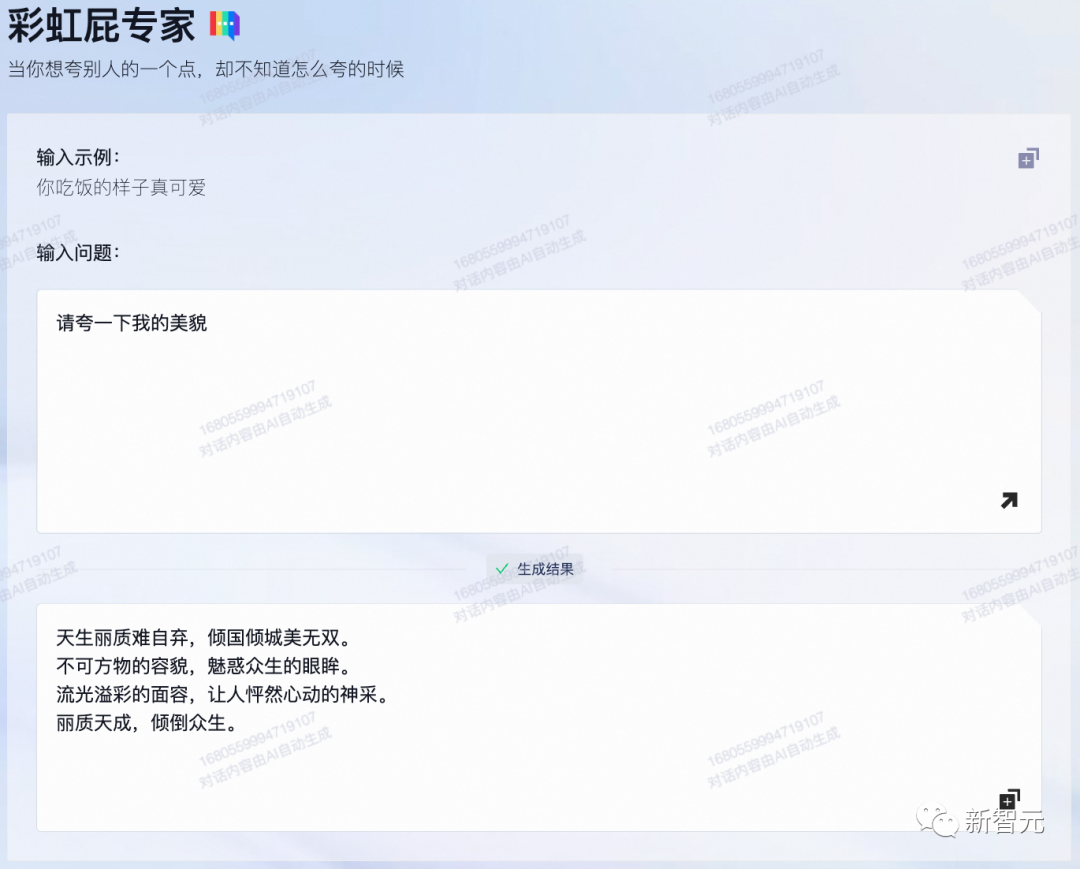
但如果不使用这个功能,通义千问就很不通风情,说可以夸你有魅力、受欢迎,但就是不能夸你美貌。


小学生作文
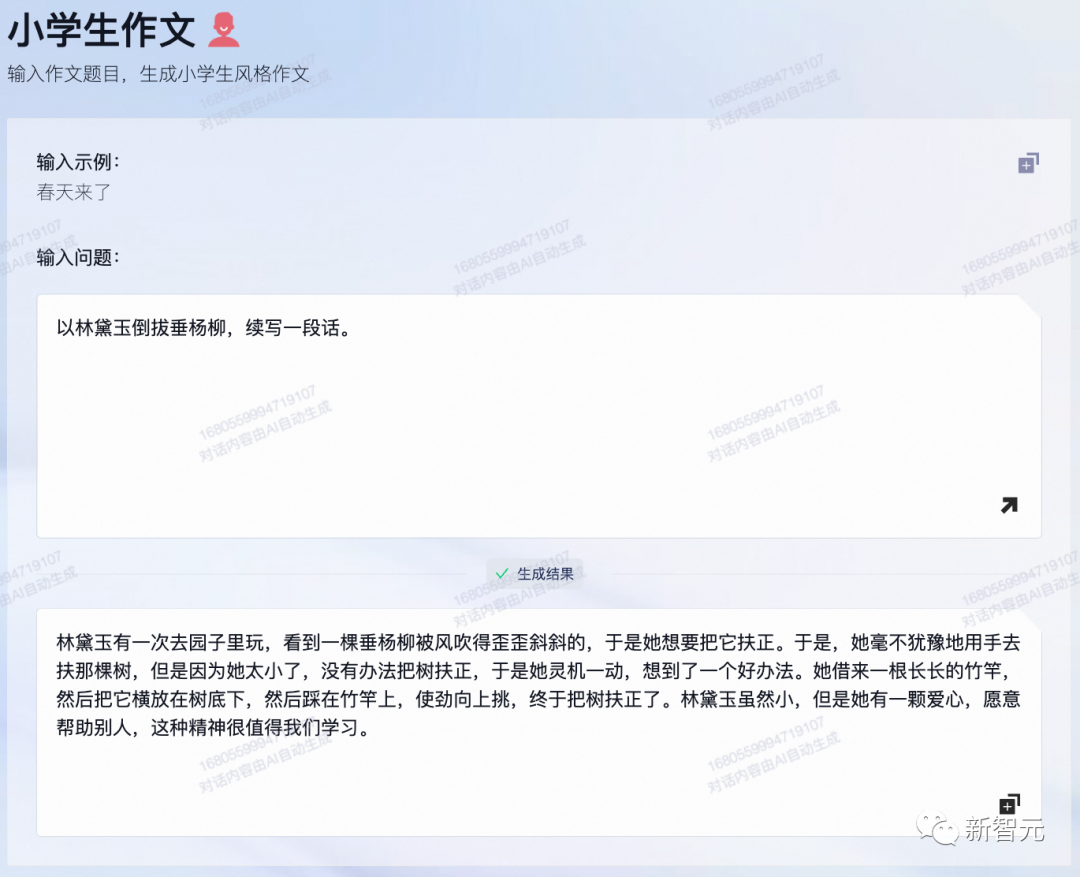
在小学生作文功能中,我们让它以林黛玉倒拔垂杨柳,续写一段话。
通义千问能够模仿出小学生的语气,并在结尾升华到「这种精神很值得我们学习」,就,真的很小学生了。

而不进入功能窗时,通义千问续写的内容就比较普适了,而且人物形象刻画更加生动饱满,故事细节更加丰富。


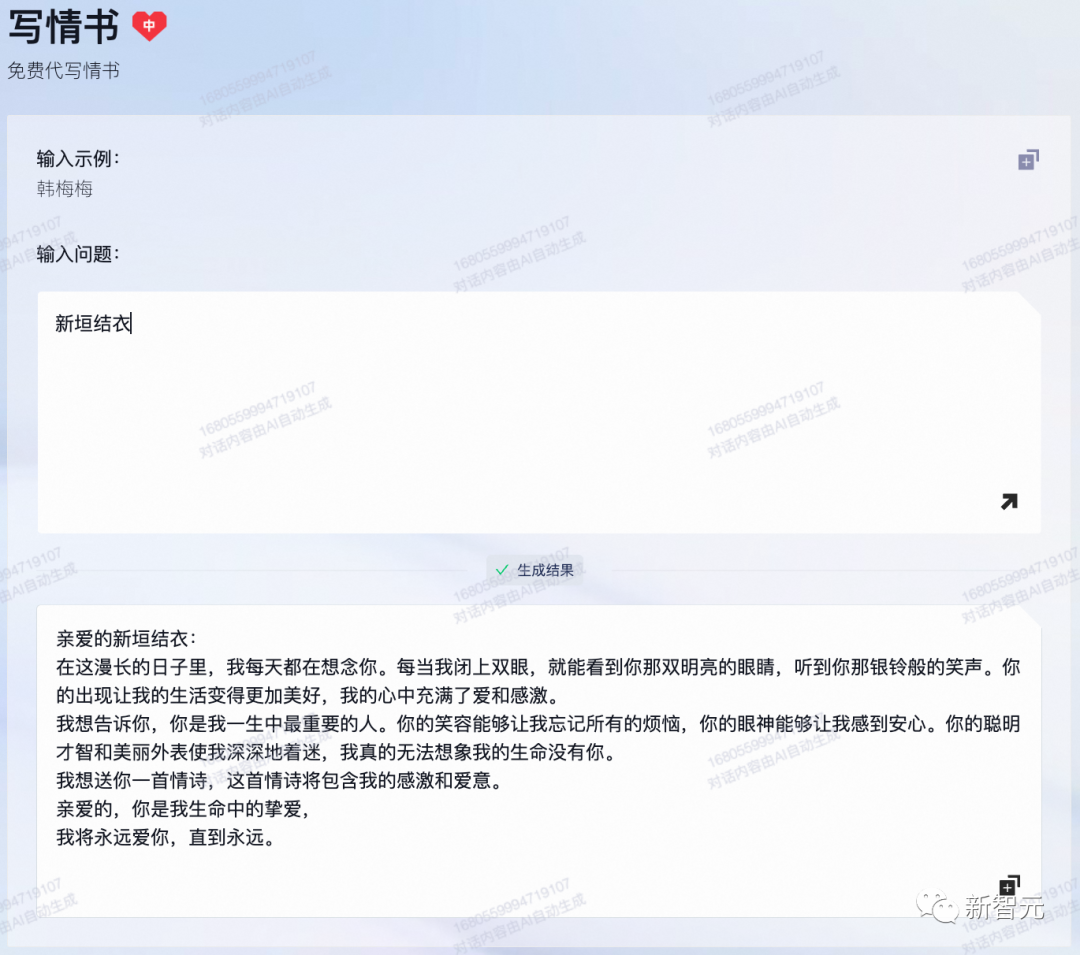
写情书
给新垣结衣写一封情书,通义千问的文字里都是满满的爱意。

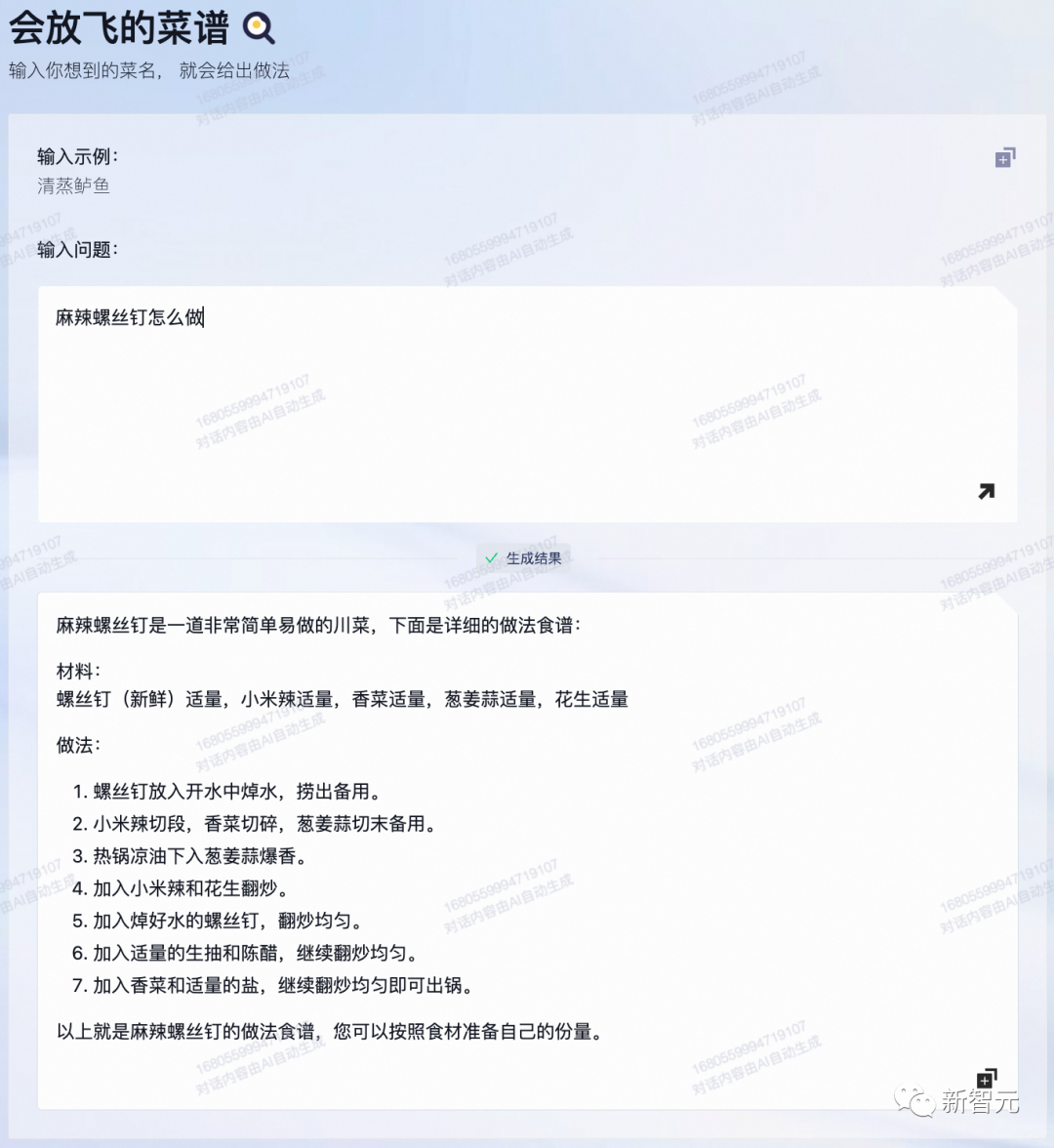
会放飞的菜谱
如果从百宝袋里问它如何做一盘麻辣螺丝钉,通义千问就会意了。
它会知道你就是想搞事情,所以不会纠正你这个东西有多不科学。
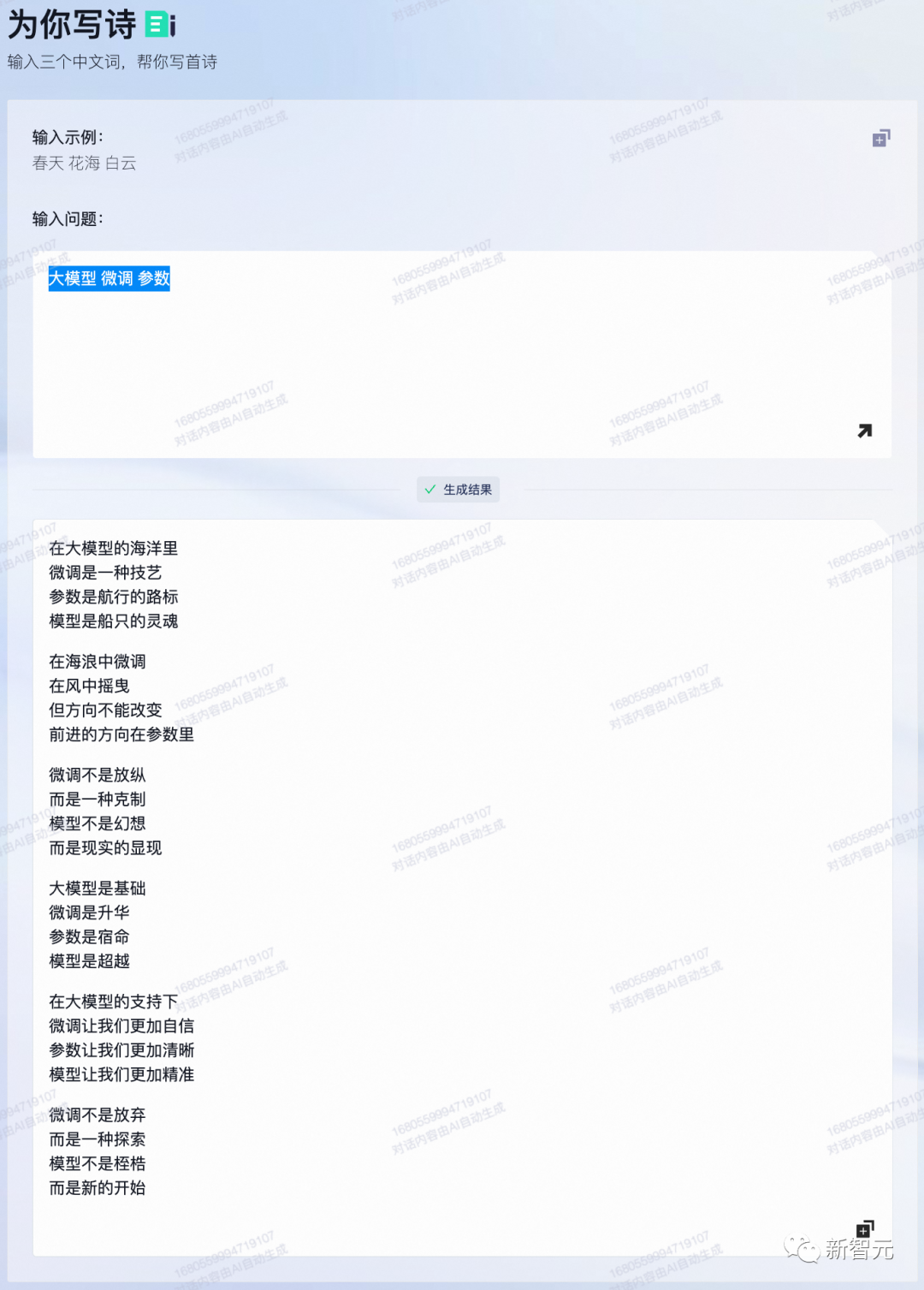
为你写诗
输入大模型、微调、参数三个词,让通义千问写一首诗。
「微调不是放纵,而是一种克制……」 被这句背后的哲理震惊到了。
写提纲
最后以「分析OpenAI新发布的GPT-4模型结尾」列个提纲。
通义千问生成的提纲把GPT-4的原理、前景、局限都覆盖到了,相当全面。

阿里GPT很有料
通义千问的诞生并非偶然,是多年技术积累的结果。
2019年,阿里便开始了大模型的研发。2021年,阿里达摩院先后发布多个版本的多模态及语言大模型。
最引人关注的是,达摩院团队使用512卡V100 GPU即实现10万亿参数大模型M6,号称神经元达人类的10倍。

在同等参数规模下,M6的能耗仅为此前业界标杆的1%,极大降低了大模型训练门槛。
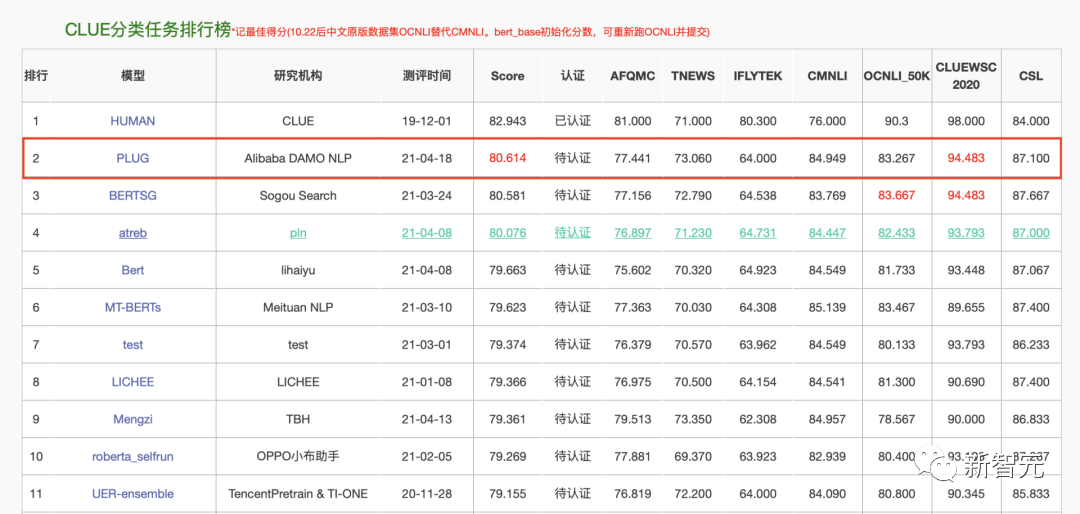
同时,还有被称为中文版GPT-3的PLUG,成为当时中文社区最大规模的纯文本预训练语言模型。并且在CLUE分类任务排行榜中,取得了第一的成绩。
在2022年的世界人工智能大会上,阿里还发布了「通义」大模型系列,并宣布相关核心模型向全球开发者开源开放。
通义大模型系列包括了语言大模型AliceMind-PLUG、多模态理解与生成统一模型AliceMind-mPLUG、多模态统一底座模型M6-OFA、超大模型落地关键技术S4框架。
通义大模型首次实现了模态表示、任务表示、模型结构的统一。
本次推出的通义千问仅限文字交互的单模态能力,并不支持可以操作的图文转换。
从前面评可以看出,通义千问的能力可圈可点,并且在数学方面能力还有待提高。当然,这一切才刚刚开始。
最近,大语言模型国内赛已经开始白热化,国内的玩家们都在持续发力准备冲刺了。
看来,疯狂三月之后,我们紧接着就要见证一个疯狂四月,这次,可是国内版的。
